The Comprehensive Guide to OCR Technology

Studies show that employees, on average, spend 30-40% of their day looking for physical documents stored traditionally in filing cabinets. By converting all essential documents to digital format, OCR technology eliminates this wasted time and improves employee productivity.
OCR stands for optical character recognition, and it’s a technology used to automatically recognize text in an image document. It’s typically used when scanning documents into a document management system.
How can you effectively manage your existing paper documents with OCR technology? Let’s find out.

Key Takeaways:
- OCR stands for optical character recognition, which is a set of technologies designed to recognize and extract text from digital images.
- OCR technology works on both scanned documents and native image files in a variety of formats, including PDF.
- OCR benefits document management by making historic paper documents searchable and more secure.
What is OCR?
Optical character recognition – OCR, for short – is a set of technologies that combine to recognize text embedded in digital image files. OCR can be used with image files in a variety of formats including PDF, JPG, and PNG. The goal is to identify and pull out relevant text information included in the images.
READ ALSO:
10 Best Paperless Document Management Software to Try in 2024
5 Best Document Management Software for Windows Users in 2024
For example, many PDF documents appear to be full of text but the files themselves are merely images of a printed page. You use OCR technology to “read” the text in the PDF file and output it as a true text file, such as a Word-formatted document.
In the office environment, OCR technology is often used when scanning paper documents into digital format. The file created with the scan is actually an image file (typically PDF format), even if you were scanning a text-based document. To turn the scanned file into a text file that can be organized and easily searched, the letters, words, and sentences of the original document must be identified and extracted using OCR software.
How Does OCR Technology Work?

Optical character recognition is a six-step process involving a variety of technologies. It works like this:
- Image acquisition: The physical document is scanned into a digital image file. (This step is skipped if the original file is natively digital.)
- Preprocessing: This trains the OCR software to recognize specific characters in image files.
- Segmentation: The digital image is broken into smaller logical parts for easier processing. (Large image files take longer to process.)
- Feature extraction: Text characters in the image are identified and extracted, typically by detecting contrasting light and dark areas.
- Classification: Pattern-recognition and feature-detection techniques are used to identify specific characters.
- Post-processing: Noise reduction and other technologies are used to clean up and remove errors from the final data.
At the end of the process, a new text file is created. That file can then be easily searched by specific keywords or phrases.
(The following video demonstrates how OCR technology works.)
How Can OCR Accuracy Be Improved?
To obtain the best results with OCR technology, you need to start with a clean and clear document. A black and white image scanned at 300 dpi will result in the most accurate character recognition.
Problems arise if the characters in the document are too bold or blurred, which can confuse the OCR software. The characters also shouldn’t be too dim or have “open” sections – which, unfortunately, is common with some copied or faxed documents.
Other issues can occur during the scanning process. Scanning sometimes introduces speckles or noise into the resulting file, which can throw off the OCR engine. Skewed text can also be an issue, as OCR technology works best with true horizontal text. It also helps if the original document uses a relatively plain font, such as Arial or Times New Roman; fancier fonts can sometimes confuse the OCR technology.
You can also ensure better results by using a high-quality document scanner. Look for a scanner that can scan at least 25 pages per minute and includes an automatic sheet feeder for batch scanning.
How is OCR Used in Document Management?
Optical character recognition is an essential part of any document management system. Just scanning a paper document into digital format isn’t really useful, as all you do is create an image of that document in PDF, JPG, or similar format. Because document management software and other apps can’t read or understand text in an image file, that makes the scanned document no more usable than the original paper document. This is why OCR technology is important. You use OCR technology to read scanned image files and extract key information into structured digital data. This is important whether you’re dealing with legal contracts, purchase orders, or other essential documents.
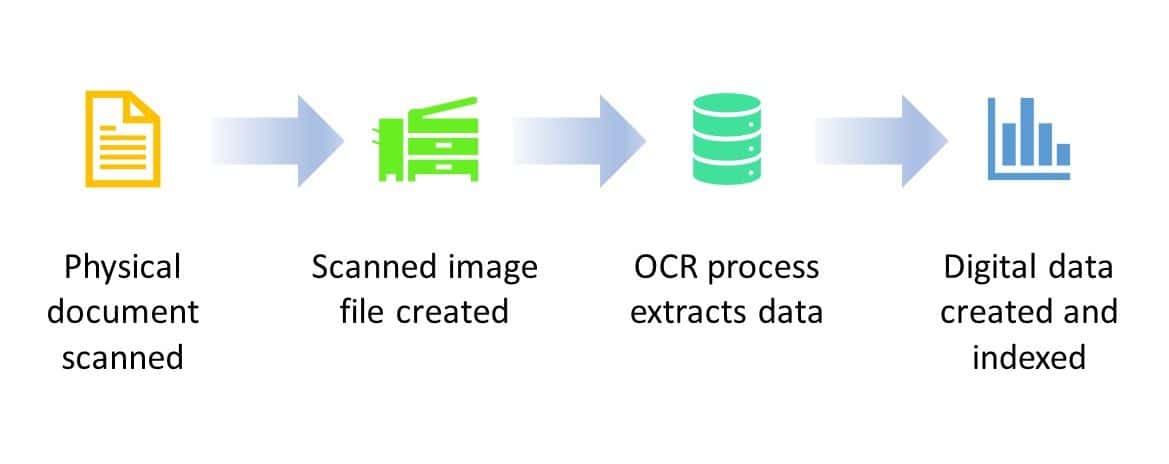
The process works like this:
- A physical document is scanned.
- The scanned image is saved as a digital image file, typically in PDF format.
- OCR software identifies and extracts the text from the scanned document and saves it to an indexed digital storage.
- Document management software identifies and indexes key data in the digital file.
The digital data extracted by OCR technology can then be securely stored, indexed, and quickly and easily searched.
Why is OCR Important for Document Management?
Document management software (DMS), sometimes known as file management software, stores, organizes, and provides searchable access to digital document files. A DMS system, such as FileCenter, stores all data in a centralized location, either on your network server or in the cloud. The goal of any document management software is to provide easy and secure file access and file sharing, reduce errors and misplaced files, improve searchability, and save your company time and money.
OCR is an integral part of DMS and provides the following benefits:
- Turns paper documents into usable digital files
- Enables fast and easy searching
- Provides enhanced security with user access controls
- Eliminates the need for physical document storage
- Saves time and money
Let FileCenter Help You Use OCR Technology
When you want to convert all your physical documents into digital files, turn to the experts at FileCenter. Our FileCenter software includes advanced OCR technology that can automatically convert scanned and image files into searchable digital data. If you have large volumes of documents that have already been scanned, our FileCenter Automate OCR software is specifically designed to OCR and convert existing documents in bulk.
All FileCenter software is easy to use and works with your own on-premises network or all major cloud services. It’s the best way to get the most value from all your current and historical documents.

Contact FileCenter today to learn more about using OCR technology in your organization!
